Tim France
-
Posts
58 -
Joined
-
Last visited
Everything posted by Tim France
-
Importing or Placing DXF in Affinity Designer 2
Tim France replied to Bruno Jolie's topic in V2 Bugs found on macOS
Hi @yesterdayjones, I can confirm that this is a (different) bug. It has been fixed and will be available in the next development cycle (2.6.0). Thanks, Tim -
QR Code Tool
Tim France replied to Ash's topic in [ARCHIVE] 2.5, 2.4, 2.3, 2.2 & 2.1 Features and Improvements
A QR Code stores only 1 payload type. If you choose URL, that QR code shape will store the URL and nothing else. You can verify this by creating a QR code with a URL and populating the vCard fields in the editor (make sure you switch back to URL after you've filled in the vCard fields). If you then save the document, restart the app, reopen the document and edit the QR code, none of the vCard fields will be populated. This is by design - there was a concern that you could accidentally leak information if all the data was stored in the QR code itself. It's the editor that remembers the last settings for each payload type. It does not persist them between app sessions or in documents. -
The button missing on Windows has been fixed, but we just missed this beta. Re AF-3024. All the other shapes retain their data across documents, so making QR codes do otherwise would be an exception to the norm that might cause more problems and confusion, so the Clear button was added as a compromise.
-
QR Code Tool
Tim France replied to Ash's topic in [ARCHIVE] 2.5, 2.4, 2.3, 2.2 & 2.1 Features and Improvements
Hi @Hangman The same effect can be achieved by reducing the size of the QR - is it that it could be specified in modules that you like? -
QR Code Tool
Tim France replied to Ash's topic in [ARCHIVE] 2.5, 2.4, 2.3, 2.2 & 2.1 Features and Improvements
Yeah... vCards are loads of fun. The vCard "spec" (it's kind of standardised in a few RFCs) states that fields are terminated with CRLF. Not LF, not paragraph separators, but "\r\n". Multiline fields (e.g. notes) must use slash n (i.e. "\\n") to escape their new lines. An earlier iteration of this editor only had a single multiline text field and I actually replaced paragraph breaks with CRLF in it, but then there's every possibility that someone will say "no no no! Don't do that! I deliberately wanted paragraph breaks in my Text data!". Here's the kicker - some versions of Android's scanner will accept some exotic unicode breaks instead of CRLF! But the iPhone I tested that on flat out rejects it. TL;DR I thought automatically replacing paragraph breaks with \r\n was a good idea but it breaks functionality for other cases. -
QR Code Tool
Tim France replied to Ash's topic in [ARCHIVE] 2.5, 2.4, 2.3, 2.2 & 2.1 Features and Improvements
It still is - you can type this in the "Text" type. Perhaps this lends support to the suggestion it should renamed "Custom" or similar. Note you should percent-escape your data though (however some QR readers don't mind if you don't) -
QR Code Tool
Tim France replied to Ash's topic in [ARCHIVE] 2.5, 2.4, 2.3, 2.2 & 2.1 Features and Improvements
The QR code objects do not retain any extra information other than their specified type. The extra information is shown and saved in the editor only so you can easily create different types of QR code without having to retype a lot of information each time. -
QR Code Tool
Tim France replied to Ash's topic in [ARCHIVE] 2.5, 2.4, 2.3, 2.2 & 2.1 Features and Improvements
My mistake. I'm sure you take the point though Anything is "legal" in a QR code - it is just text (technically it doesn't even have to be that - you can have raw byte data if you like). The only thing that makes a particular type is how it is formatted / constructed and if it is supported by the QR reader. There aren't any official standards, just conventions that most QR readers follow... but even those differ between Android and iOS. -
QR Code Tool
Tim France replied to Ash's topic in [ARCHIVE] 2.5, 2.4, 2.3, 2.2 & 2.1 Features and Improvements
What about the American style 1-800-CALLDAVE? -
QR Code Tool
Tim France replied to Ash's topic in [ARCHIVE] 2.5, 2.4, 2.3, 2.2 & 2.1 Features and Improvements
Yep, I think that's fair! -
QR Code Tool
Tim France replied to Ash's topic in [ARCHIVE] 2.5, 2.4, 2.3, 2.2 & 2.1 Features and Improvements
Well... maybe. But the WhatsApp help specifically states the link should be formatted as described in the tooltip. See https://faq.whatsapp.com/5913398998672934 You could argue that it strip leading zeros, but that leads to this next problem: There is no standardised format for phone numbers, so validating it isn't really feasible. Even if I tried to validate against some common formats (I did initially), there are many locale-specific rules and conventions that don't follow them, but are valid in certain regions. I felt it best to leave it up to the user to get it right. Going back to WhatsApp, I could strip zeros, but then should + be stripped too? What about spaces? The automagic could significantly change the number. I think the most sensible approach is to validate against the official WhatsApp spec. -
Hi @Seneca, I don't really have anything specific to say other than the team is still smashing out APIs! We've also had to go back and do some of the less interesting "that can wait" tasks, such as dealing with shut down properly e.g. you start running a script and then decide to shut down the app halfway through its execution - we need to make sure things like asynchronous ops are properly aborted / synchronous waits end gracefully. We've also been re-evaluating the high level JS layers to make sure they were intuitive and usable. We went hell for leather to get bits of the app exposed, but didn't do them in a particularly good way e.g. this kind of sucks: let clrData = new RGBA8(0, 0, 255); let clr = new Colour(clrData); and should be something much more concise like: let clr = RGB(0, 0, 255);
- 808 replies
-
- 9
-

-

-
- automation
- scripting
- (and 3 more)
-
Hi @kimtorch, Could you clarify on what you mean? Are you referring to parsing some text with tags in them or do you mean tagging text frames / individual bits of text with a tag and then have a script use those tags to find and manipulate bits of text? I'm assuming the latter because the former doesn't require app support - it would just be a case of writing a script to parse the text. If you mean tagging bits of the DOM (like text frames) or individual glyphs within a story, that is something we're already considering. Could you describe a standard use case?
- 808 replies
-
- 1
-
-
- automation
- scripting
- (and 3 more)
-
This. The scripting devs are going to have to dedicate a significant amount of time towards documentation. We can't expect our docs team to document the ins and outs of an API (technically multiple APIs), it's simply not fair or realistic. Besides, we'd have to tell them what to write, which would mean pretty much writing the documentation anyway. Sure, they'll be able to present it in a way that looks good and integrated with the normal app documentation, but the devs are going to have to provide much of the content. We're planning to use one of the many available documentation tools to do most of actual generation for us. The current favourite is Doxygen, largely because most of us have had at least some exposure to it. Please remember too that the scripting team sometimes has to do bits of work away from scripting development. As the dev who wrote the DWG/DXF importer (and now exporter - see here 🙂), I tend to be the one tasked with its fixes and improvements. The same goes for Move and Shape Data Entry. Everyone in dev could put in those fixes, but it makes so much more sense if I do them because I'm most familiar with the code and should be able to do the work faster. The members of the scripting team do spend most of their time doing scripting work, but it's not 100%.
- 808 replies
-
- 13
-
-
-
- automation
- scripting
- (and 3 more)
-
Importing or Placing DXF in Affinity Designer 2
Tim France replied to Bruno Jolie's topic in V2 Bugs found on macOS
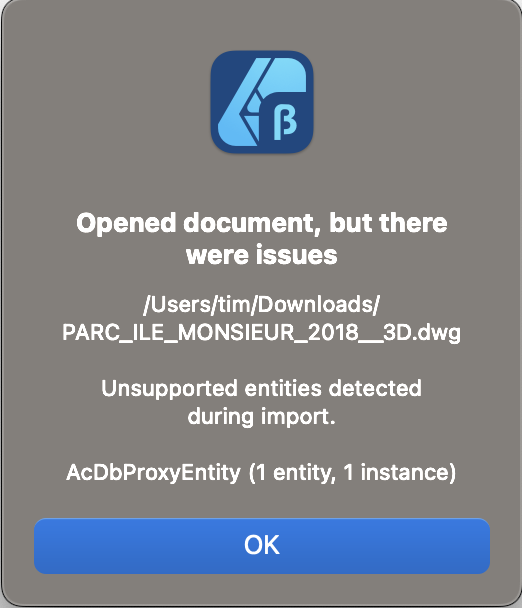
Hi @Bruno Jolie, I've taken a look at your file and can confirm it is a bug in Affinity. The problem is the file contains a single Polyface Mesh, an entity that Affinity does not support. Once we've skipped over that during import, there is nothing left in the document and due to a particular set of circumstances, things go wrong. I've fixed the crash and while I was in that area, I added support for polyface meshes. The changes will appear in a future version of Affinity (likely to be 2.4) Tim -
Hi all, The team has been making good progress. I don't have any updates on a release date but please be assured we are not sitting on our haunches - we want to get this feature out as much as you want it out! Naturally we've been exposing more of the apps' functionality to scripts, but we've been working on plugin-specific technology too. For example, there's a new asynchronous file i/o and networking API, initially driven by the Javascript layer but then we thought it would be good for the lower level C/C++ plugins to have access too. Obviously with local and remote i/o, we've had to be careful that a script isn't covertly sending user data somewhere, so we've introduced a permissions system for Javascript plugins - unless you allow a particular script network access, it won't be able to use the networking API. It may not be a big shiny WOW! feature, but it's important to get these things right. Anecdotally, I can tell you we've actually used some scripts internally to do some genuinely useful stuff that would have taken literally days to do manually. One script I wrote optimised a document and removed about 60000 layers. There have also been relatively simple layout and alignment tasks that scripts can munch through in the blink of an eye. Last week I wrote a script that split a pixel layer into new pixel layers containing the blocks of grouped pixels. Even the pixel processing was done in the script - I didn't have to rely on the app to do the heavy lifting for me because our performance is good enough to implement DBSCAN in Javascript. Please be patient. We know you all want scripting available yesterday, but we're getting there!
- 808 replies
-
- 32
-
-
-
- automation
- scripting
- (and 3 more)
-
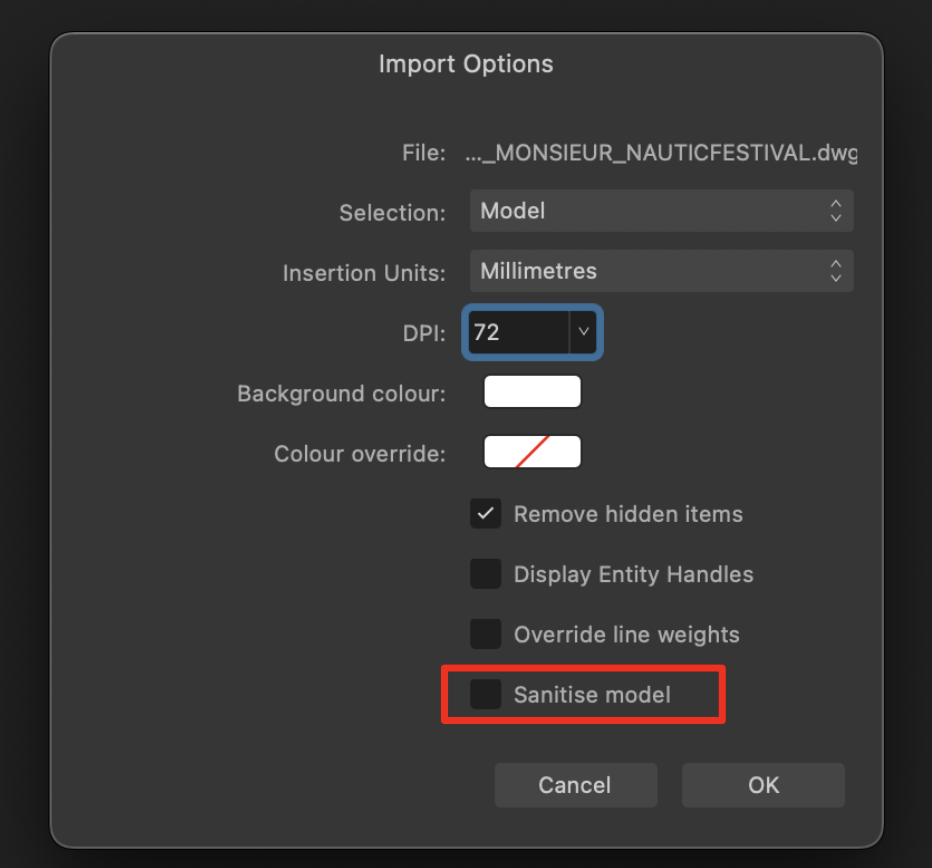
You may like to try out the latest beta, in particular this new options:

-
You could perhaps argue a slider would work for the angle and rotation values but the others are unbounded, so it's hard to choose a sensible range for the slider.
-
If I hack a very crude filter into Designer that simply removes anything that is a 4E7 value away from (0,0), your file is imported like this:
-
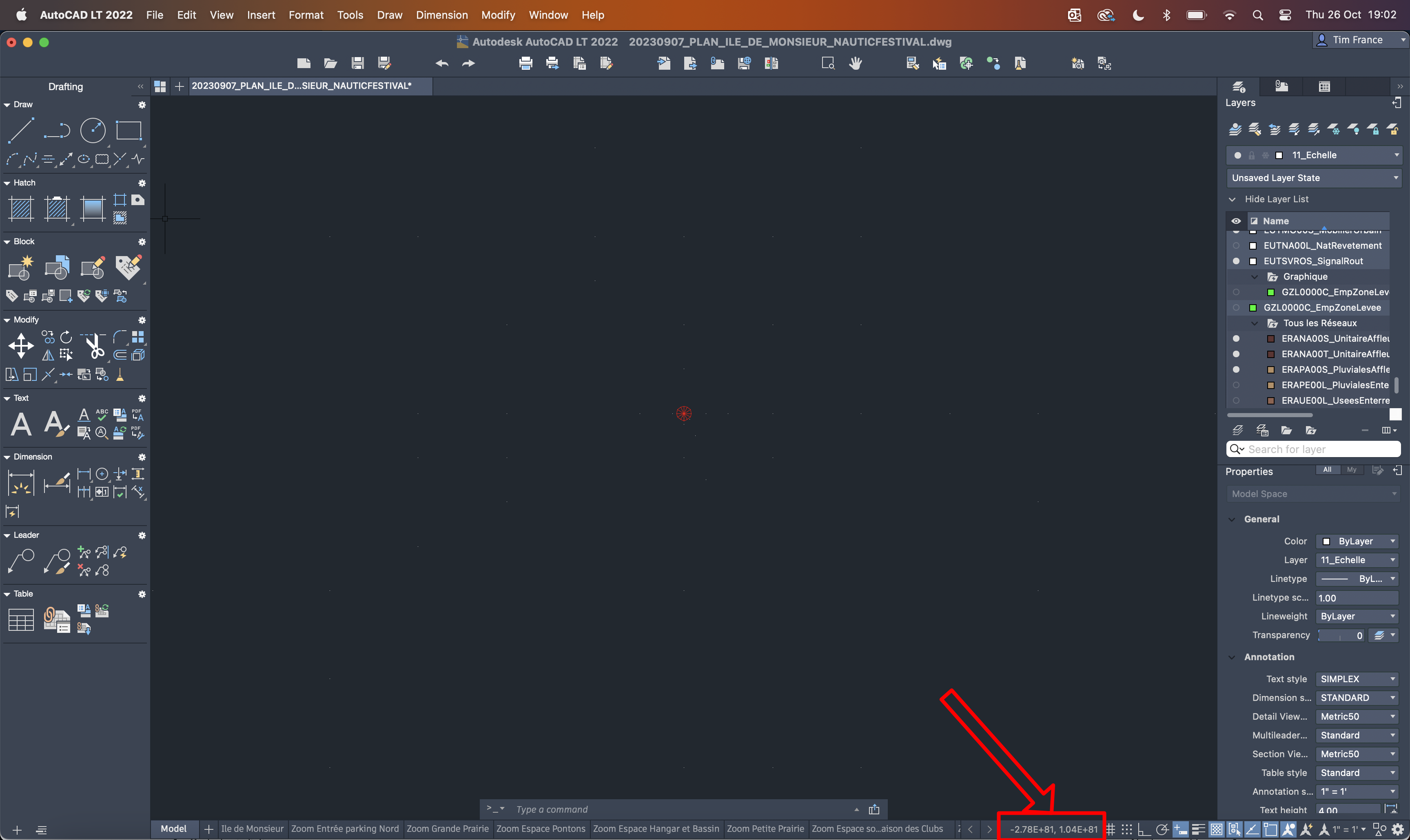
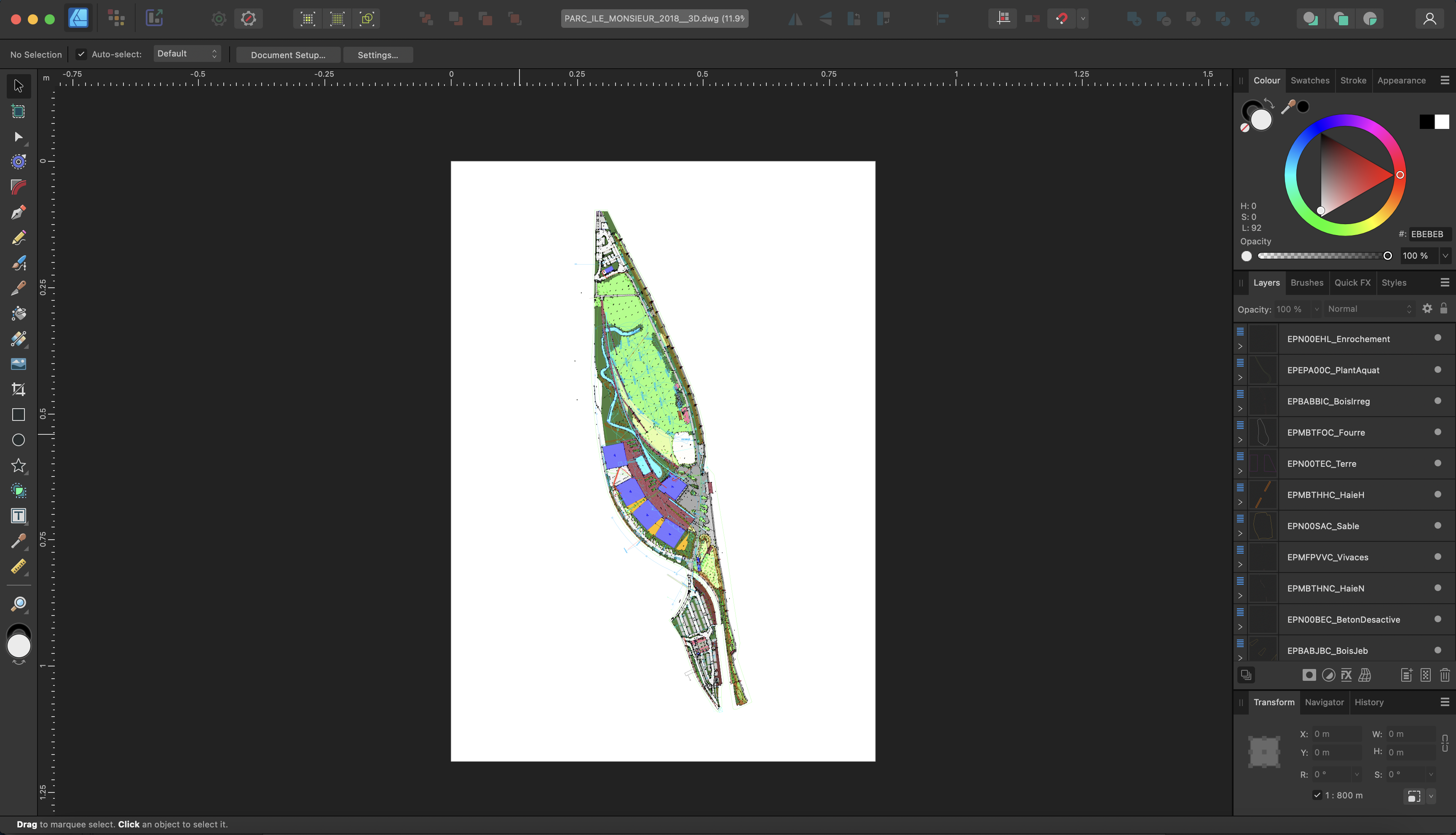
Hi @julwest78, I've taken a closer look and it's a tough problem to solve. The trouble is your model has entities in it that are spread across a huge distance. Open the file in AutoCAD, then go View -> Zoom -> All, then hover over the middle of your model view. Take a look at the coordinates in the status bar at the bottom of AutoCAD: If you go to the bottom left corner, the coordinate read out is (-2.5E81, -2.1E81) whereas the top right corner is (2.8E81, 1.7E81). If you're not familiar with scientific notation, 1E81 means 1 with 81 zeroes after it. To fit all of those onto a sensibly sized spread, Designer has to scale the entities down by a huge scale factor. AutoCAD doesn't have this problem because the model is boundless space but Designer has to specify a page size and you can't specify a page that is 1E80mm across - that's greater than the size of the observable universe! Some entities are positioned normally within a relatively normal range (about 1E6). Unfortunately even those start to break down when you have to multiply them by such extreme scale factors, so I don't think there's much Designer can do with this document without it being edited first Ideally you would select the entities you want to keep and then invert the selection, but as far as I'm aware, AutoCAD doesn't provide a "Select Inverse" option. I'll have a think and see if there's anything easy I can add but if you can get the document cleaned up somehow I think you'll have much more success.
-
I see - this is a different file, but exhibiting the same problems. I will take a look.
-
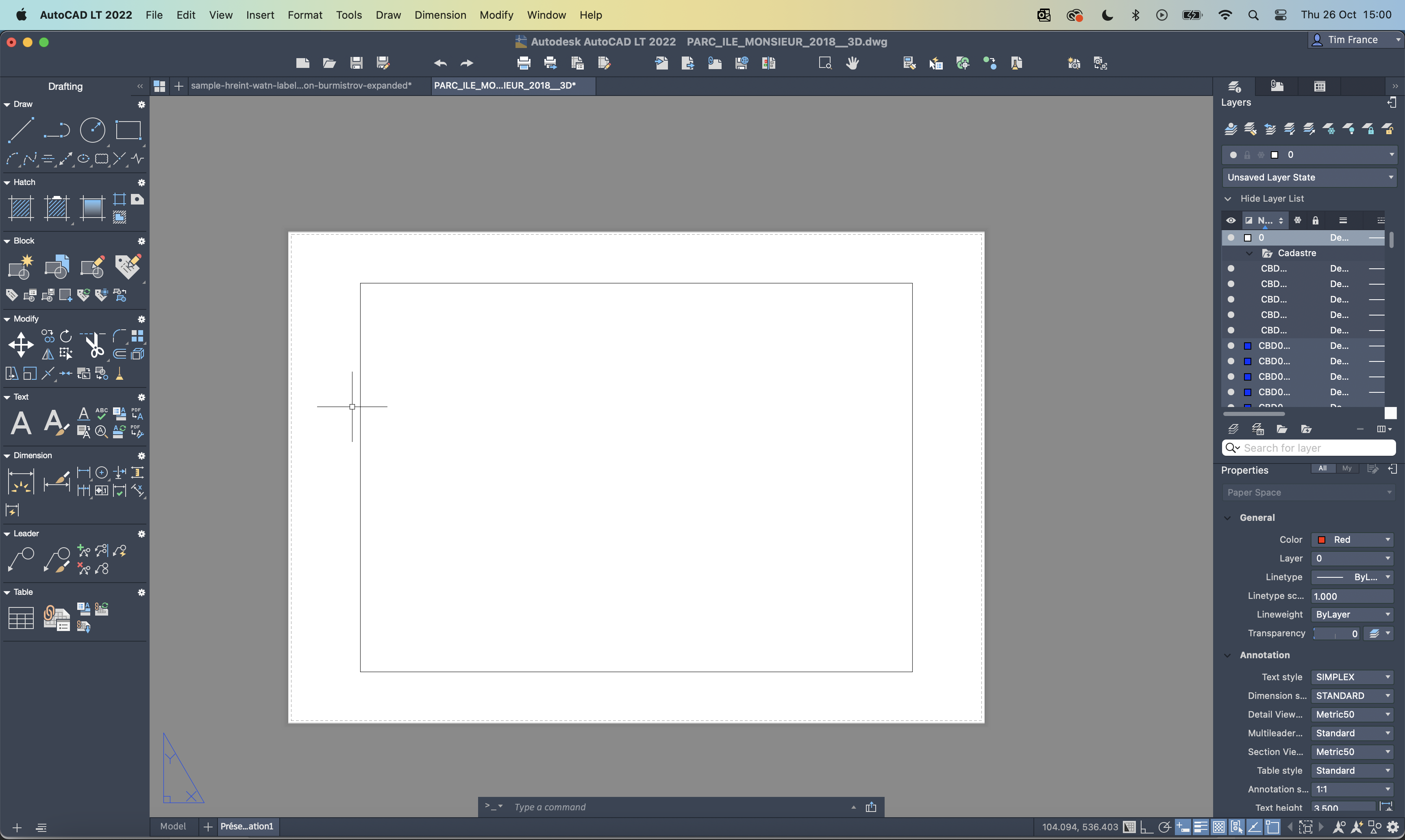
@julwest78 Are you selecting "Model" in the import options? The paper-space layout ("Presentation1") is empty, as shown in AutoCAD: However if you select Model, Designer imports this: The warning about the proxy entity is still valid - AutoCAD essentially gives you the same warning - but it should not affect the import.
-
Thanks for spotting that. The behaviour on Windows is a little different to on macOS, the latter being correct. Changing the tool should dismiss the dialog and hitting enter with the Node Tool selected doesn't bring up the dialog if you have anything with curve nodes selected (there's a good reason for this...). The Windows version will be fixed in the next beta.
-
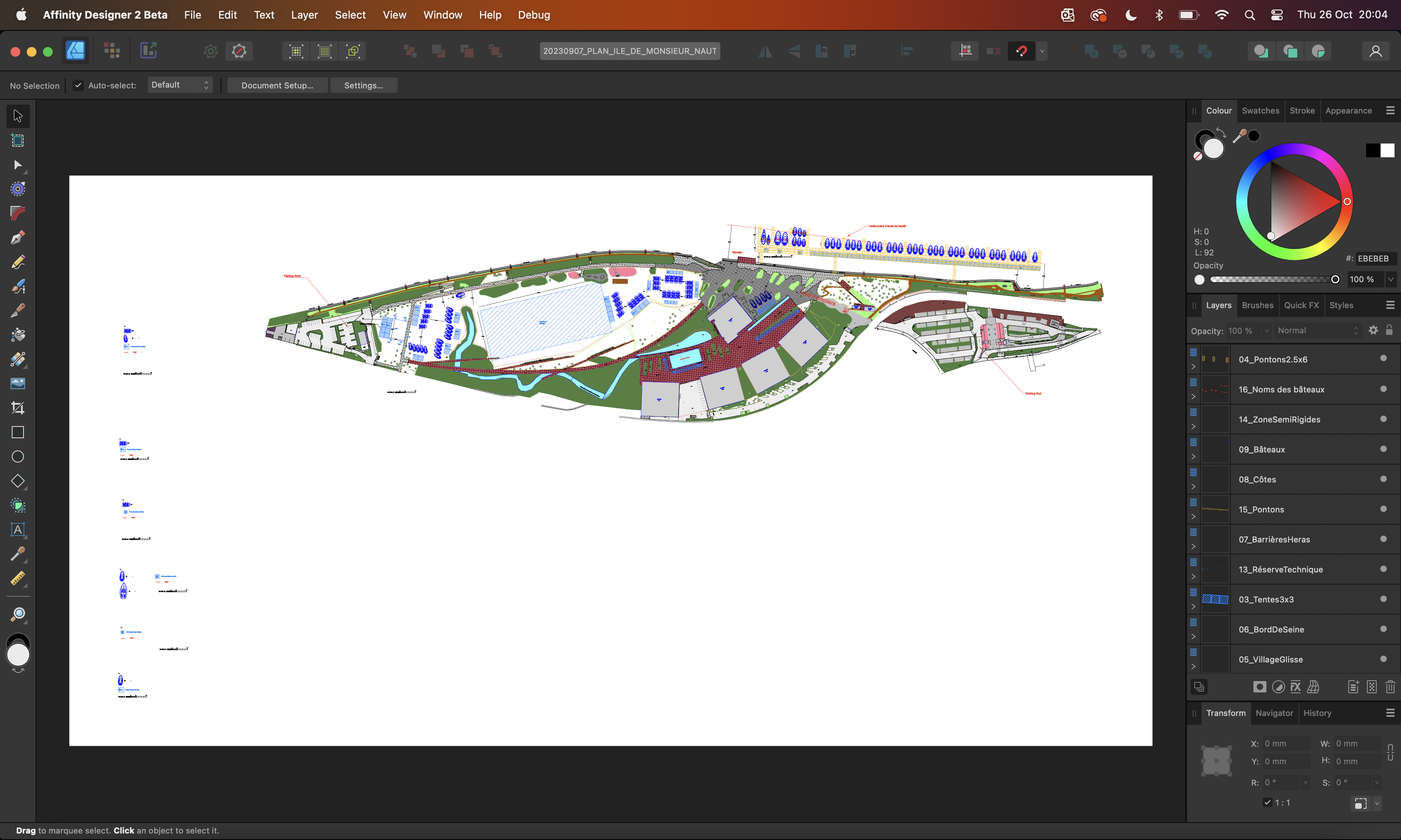
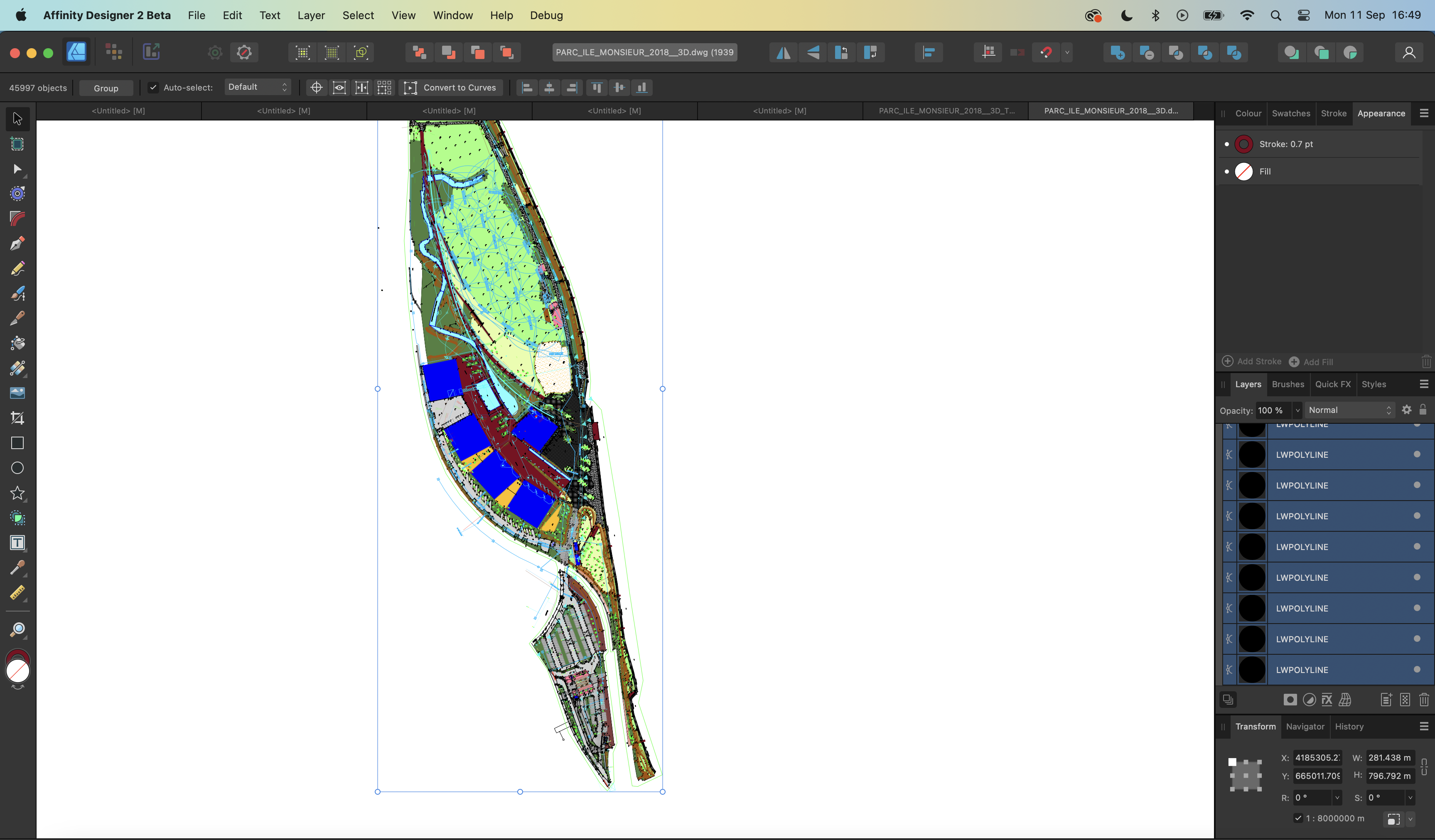
@julwest78 I have good news and some not-so-good news. The good news is I've found the reason for the bad import and have put a fix into Designer. Now your file will open normally and look like this: The not-so-good news is it is highly unlikely I'll be able to get the fix into v2.2 as we're quite far through the beta cycle, so unfortunately this will probably have to wait till v2.3. Regards, Tim
-
Hi @julwest78, I've taken a look at your file. There is a proxy entity in it, which designer warns you about when it opens the file, but I don't think they are the cause of your problems. If you choose "Single Page" on import and select the only paperspace layout available (called "Presentation1") you get a blank document. This is correct behaviour and AutoCAD does the same thing: If you choose "Model" on import, Designer imports the document but has had to zoom out by such a huge amount, you can't see anything. That's because Designer thinks some of the entities in the model are a huge distance from the rest of them and to display all of them, it zooms out. If you do a Select All (Cmd+A or Ctrl+A), you will see a bounding box around all of the entities and that box is massive. If you zoom in on the corner of the box that's on the spread and enable Hairline View mode (View -> View Mode -> Hairline), you will see your entities appear: You could select just these entities and paste them into a new document, then scale / rotate them as a work around. I will see if there's a legitimate reason why Designer thinks there are these huge entities in your document (like in Layer ERLBT00L_ElectriciteBT). Regards, Tim